[1] "state,abb,region,population,total" "Alabama,AL,South,4779736,135"
[3] "Alaska,AK,West,710231,19" Data Importing
MATH/COSC 3570 Introduction to Data Science






DBI, jsonline, xml2, httr
R Data Importing
Missing Values
Which type is the column vector x? Why?
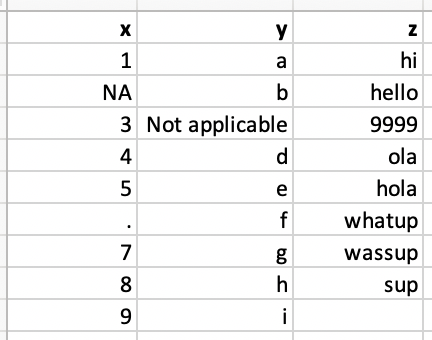
Solution 1: Explicit NAs
- By default,
read_csv()only recognizes ” “ and NA as a missing value. - Specify the values that are used to represent missing values by argument
na.
pd.DataFrame.to_csv
w = {"x":[1, 2, 3],
"y":['a', 'b','c']}
wdf = pd.DataFrame(w)
wdf.to_csv("./data/wdf.csv")
mydf = pd.read_csv('./data/wdf.csv')
mydf.head() Unnamed: 0 x y
0 0 1 a
1 1 2 b
2 2 3 c## index = False means don't write row names
wdf.to_csv("./data/wdf.csv", index = False)
mydf = pd.read_csv('./data/wdf.csv')
mydf.head() x y
0 1 a
1 2 b
2 3 c![]()