Data Wrangling - two data frames 🛠
MATH/COSC 3570 Introduction to Data Science
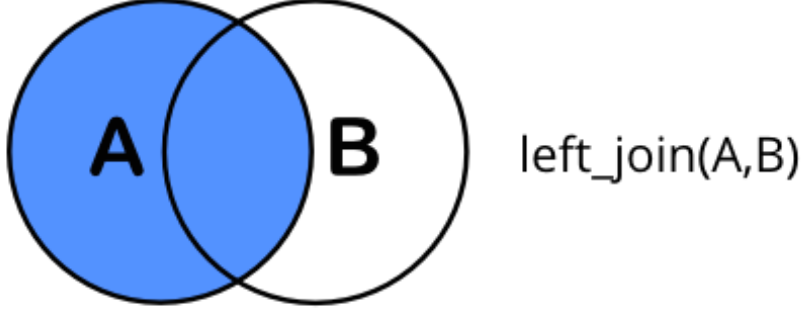
left_join(x, y): all rows from x
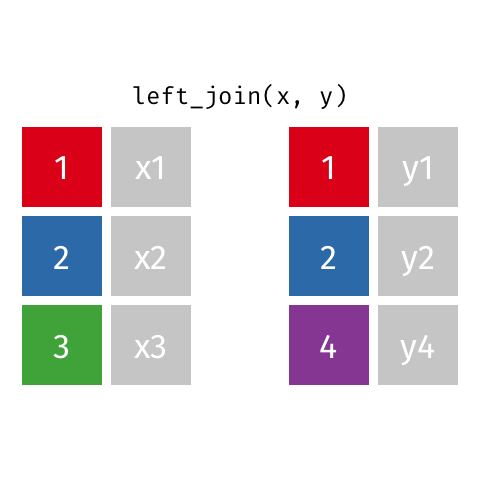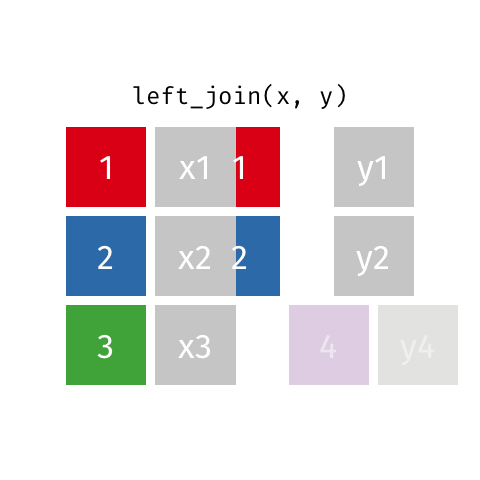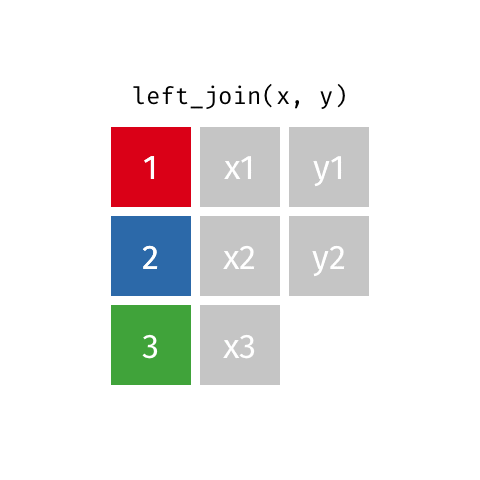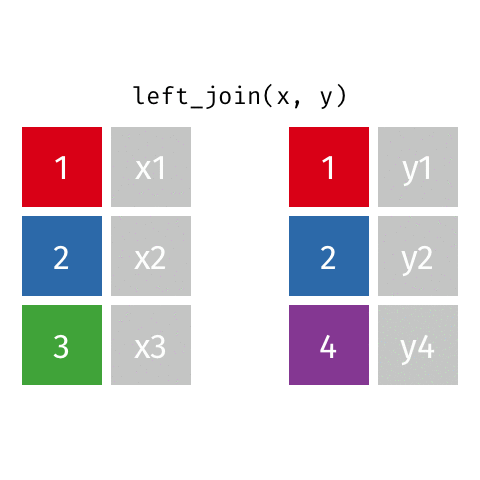
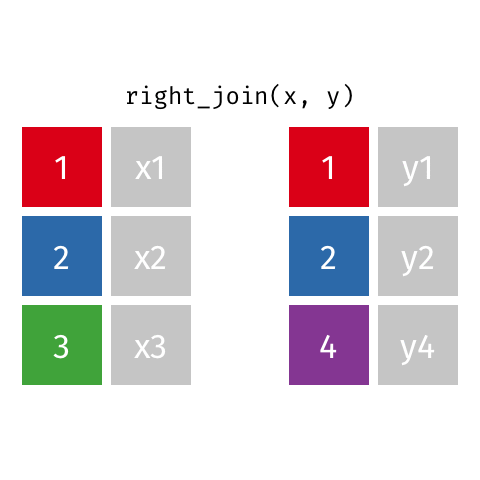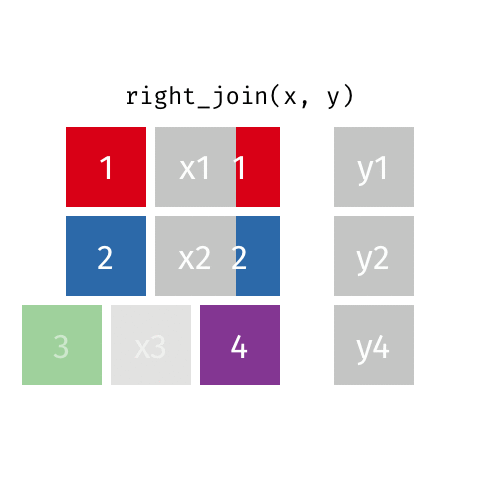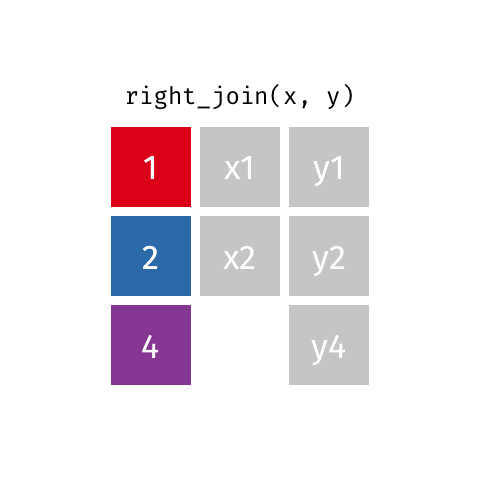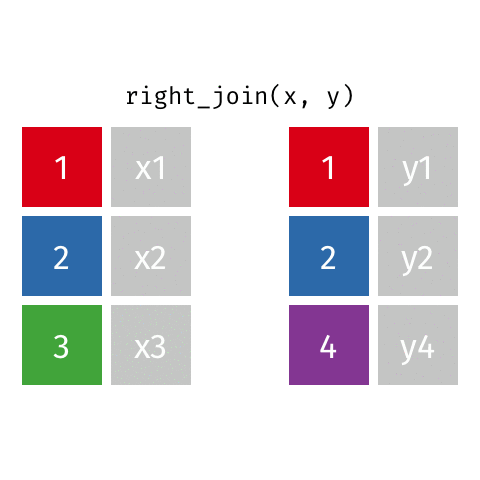
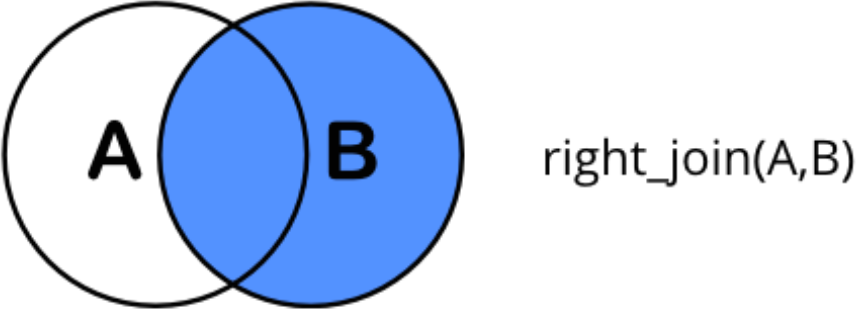
right_join(x, y): all rows from y
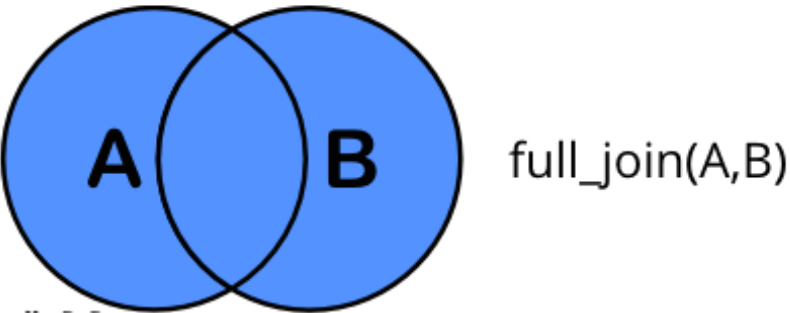
full_join(x, y): all rows from both x and y

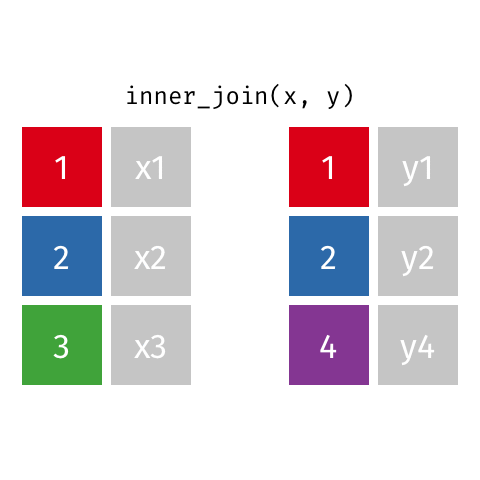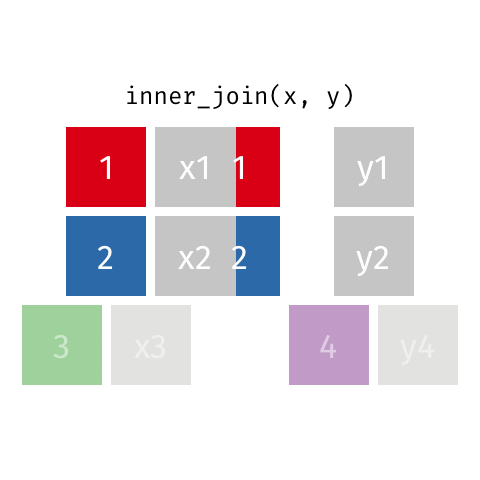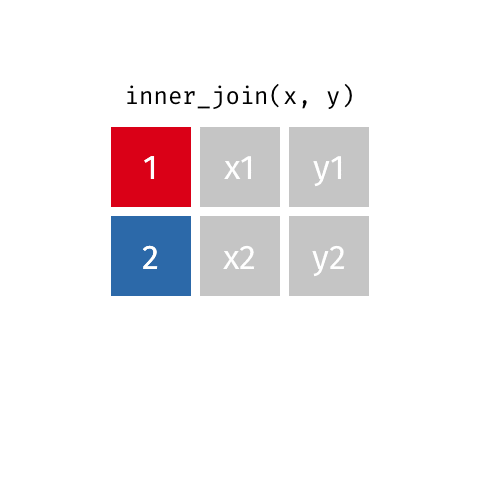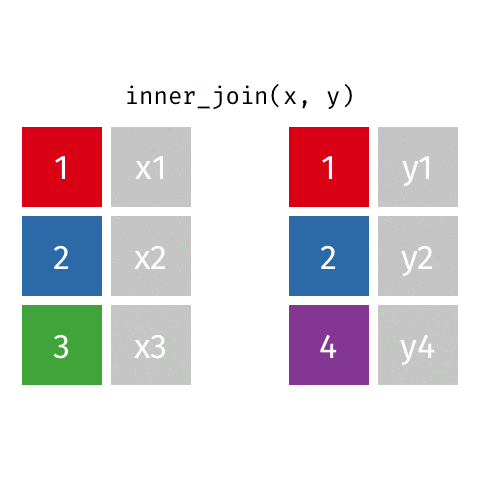
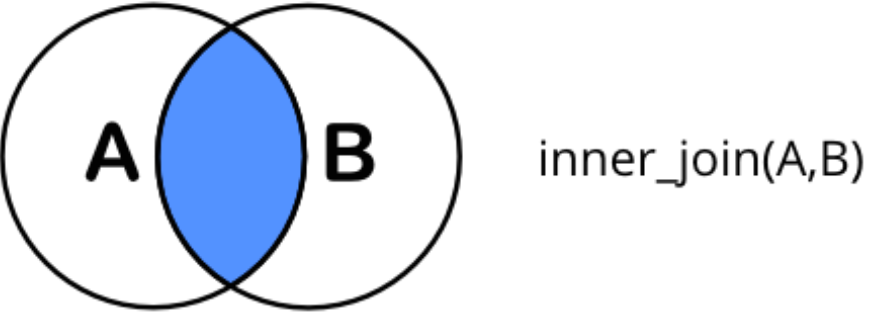
inner_join(x, y): only rows w/ keys in both x and y
# A tibble: 53,940 × 4
carat color Description Details
<dbl> <chr> <chr> <chr>
1 0.23 E Colorless Minute traces of color
2 0.21 E Colorless Minute traces of color
3 0.23 E Colorless Minute traces of color
4 0.29 I Near Colorless Slightly detectable color
5 0.31 J Near Colorless Slightly detectable color
6 0.24 J Near Colorless Slightly detectable color
# ℹ 53,934 more rows
state population electoral_votes
0 Alabama 4779736.0 9
1 Alaska 710231.0 3
2 Arizona 6392017.0 11
3 California 37253956.0 55
4 Connecticut NaN 7
5 Delaware NaN 3