Linear Regression
MATH/COSC 3570 Introduction to Data Science
Simple Linear Regression
\[\begin{align*} y_i &= f(x_i) + \epsilon_i \\ &= \beta_0 + \beta_1~x_{i} + \epsilon_i, \quad i = 1, 2, \dots, n \end{align*}\]
- \(\beta_0\) and \(\beta_1\) are unknown parameters to be learned or estimated.
What are the assumption on \(\epsilon_i\)?
\(\epsilon_i \sim N(0, \sigma^2)\) and hence \(y_i \mid x_i \sim N(\beta_0+\beta_1x_i, \sigma^2)\)
Simple Linear Regression Assumptions
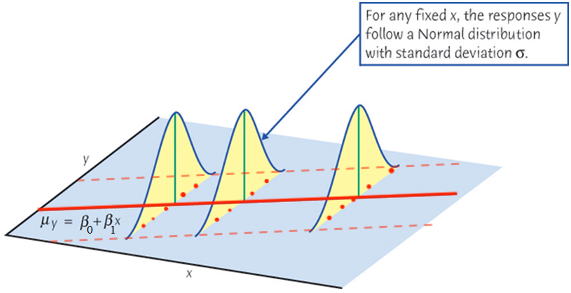
Simple Linear Regression Assumptions
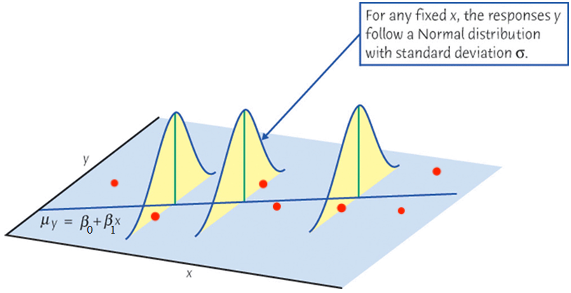
Simple Linear Regression Assumptions
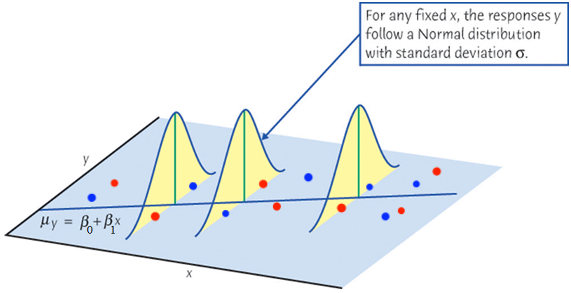
Visualizing Residuals
Visualizing Residuals (cont.)
Visualizing Residuals (cont.)
Predict Highway MPG hwy from Displacement displ
\[\widehat{hwy}_{i} = b_0 + b_1 \times displ_{i}\]









Tidymodels
Step 1: Specify Model: linear_reg()
Linear Regression Model Specification (regression)
Computational engine: lm parsnip package provides a tidy, unified interface for fitting models
Quantify Uncertainty about Mean of \(y\)
p <- ggplot(data = reg_out_fit,
aes(x = displ, y = hwy)) +
geom_point(alpha = 0.3) +
labs(title = "Highway MPG vs. Engine Displacement",
x = "Displacement (litres)",
y = "Highway miles per gallon") +
coord_cartesian(ylim = c(11, 44))
p_ci <- p + geom_smooth(method = "lm",
color = "#003366",
fill = "blue",
se = TRUE)Quantify Uncertainty about Individual \(y\)
Graphical Diagnostics: Residual Plot
- Residuals distributed randomly around 0.
- Check it by plotting residuals against the fitted value of \(y\): \(e_i\) vs. \(\hat{y}_i\)
- With no visible pattern along the x or y axis.
Not looking for…
Fan shapes
Not looking for…
Groups of patterns
Not looking for…
Residuals correlated with predicted values
Not looking for…
Any patterns!
MPG Data Residuals