Principal Component Analysis
MATH/COSC 3570 Introduction to Data Science
One-Dimension (1D) Number line
One-Dimension (1D) Number line: Uniform students
1D Number line: Non-uniform students
Two-Dimensions (2D) X-Y Scatter plot: High Correlated
English and Math measure an overall academic performance.
Two-Dimensions (2D) X-Y Scatter plot: No correlated
English and Math measure different abilities.
Three-Dimensions (3D) X-Y-Z Scatter plot
Four-Dimensions (4D) X-Y-Z-? Scatter plot

How about Pair Plots?
Variation mostly from One Variable
- Almost all of the variation in the data is from left to right.
Variation mostly from One Variable
- If we flattened the data, the graph would not look much different.
Variation mostly from One Variable
- If we flattened the data, we could graph it with a 1D number line!
Variation mostly from One Variable
- Both graphs say “the important variation is left to right.”
PCA Illustration: 2 Variable Example
Step 1: Shift (or standardize) the Data
- So the two variables have both mean 0. If the variables are measured in a different unit, consider standardization, \(\frac{x_i - \bar{x}}{s_x}\).
- Shifting does not change how the data points are positioned relative to each other.
Step 2: Find a Line that Fits the Data the Best
- Start with a line going through the origin.
- Rotate the line until it fits the data as well as it can, given that it goes through the origin.

Step 2: Find a Line that Fits the Data the Best
- Start with a line going through the origin.
- Rotate the line until it fits the data as well as it can, given that it goes through the origin.
Step 2: Find a Line that Fits the Data the Best
- Start with a line going through the origin.
- Rotate the line until it fits the data as well as it can, given that it goes through the origin.
The Meaning of the Best line
The best line maximizes the variance of the projected points from the data points onto the line! It is called the 1st Principal Component (PC1)
-
PC1 is the line in the Eng-Math space that is closest to the \(n\) observations
- PC1 minimizes the sum of squared distances between the data points and the PC1.
PC1 is the best 1D representation of the 2D data

The Meaning of the Best line
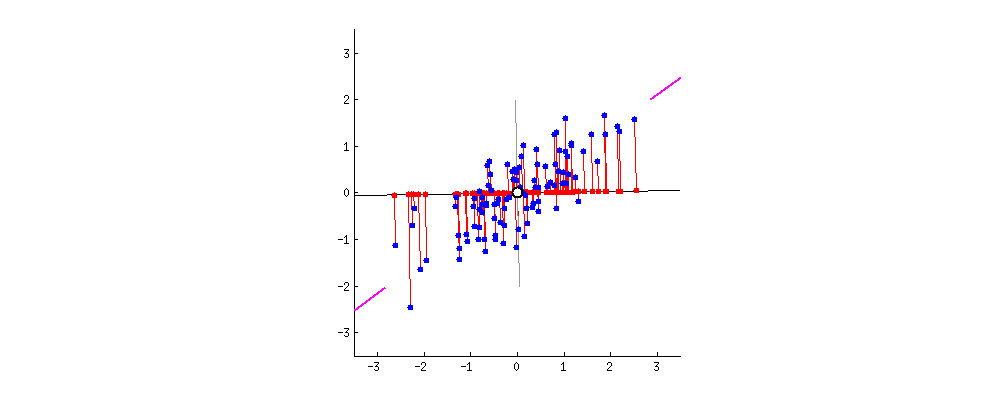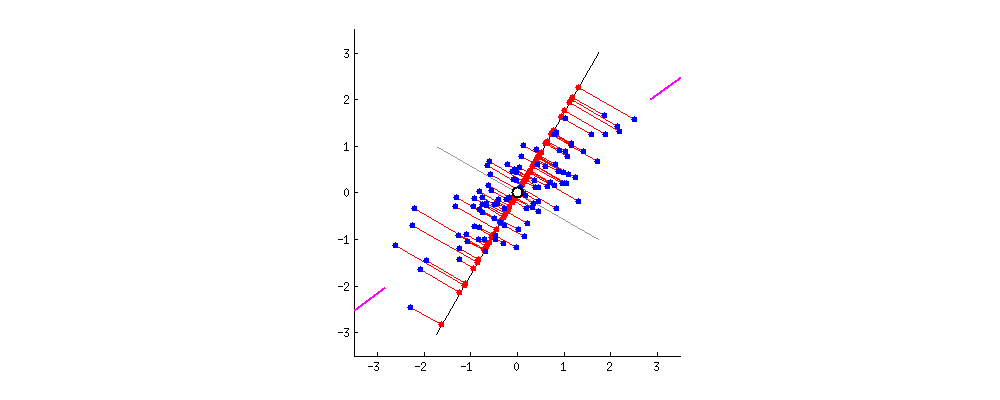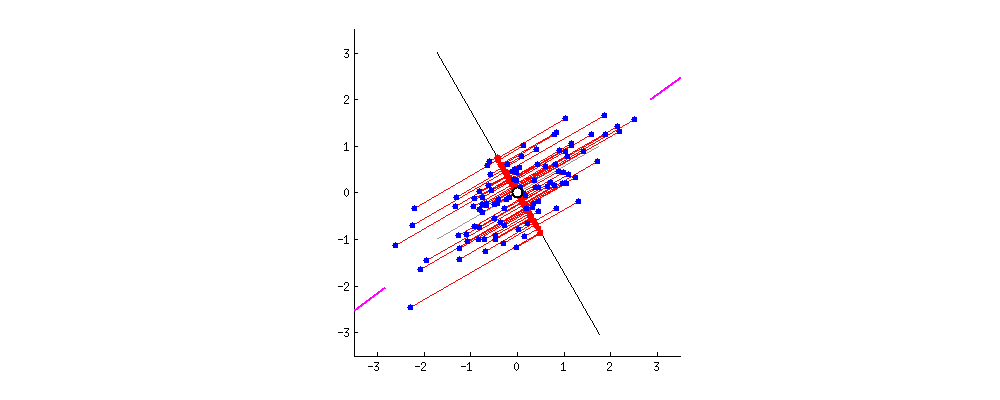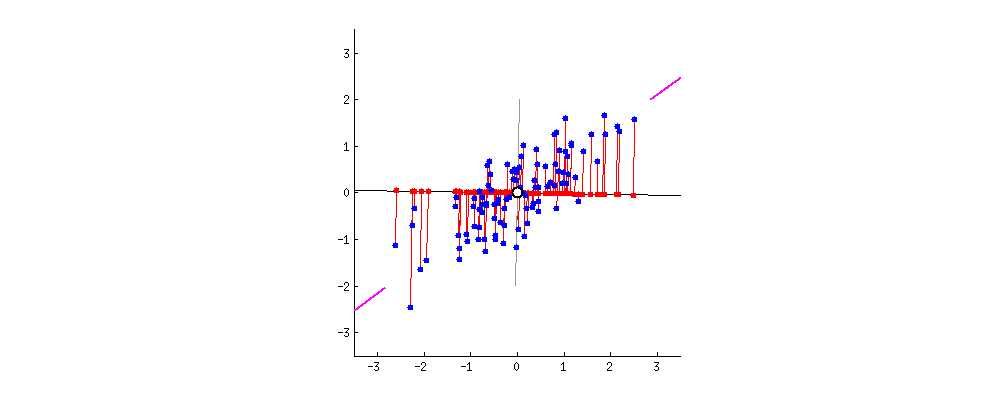
PC1 and PC2
- The data points are also spread out a little above and below the PC1.
- There are some variation that is not explained by the PC1.
- Find the second PC, PC2, that
- explains the remaining variation
- is the line through the origin and perpendicular to PC1.
Linear Combinations

- PC1 = 0.68 \(\times\) English \(+\) 0.74 \(\times\) Math
- PC2 = 0.74 \(\times\) English \(-\) 0.68 \(\times\) Math
- PC1 is like an overall intelligence index as it is a weighted average combining verbal and quantitative abilities.
- PC2 accounts for individual difference in English and Math scores.
- The combination weights 0.68, 0.74, etc are called PC loadings.
2D Representation of the 4D data
2D Representation of the 4D data: biplot
- Top axis: PC1 loadings
- Right axis: PC2 loadings
- Red arrows: PC1 and PC2 loading vector, e.g., (0.28, -0.87) for
UrbanPop. - Crime-related variables (
Assualt,MurderandRape) are located close to each other. -
UrbanPopis far from the other three. -
Assualt,MurderandRapeare more correlated, andUrbanPopis less correlated with the other three.
Scree Plot
Look for a point at which the proportion of variance explained by each subsequent PC drops off.

-
Data on PCs (
pca_output$x)
X_pc = np.round(pca.transform(X), 2)
pd.DataFrame(X_pc, columns=['PC1', 'PC2', 'PC3', 'PC4'], index=USArr.index) PC1 PC2 PC3 PC4
rownames
Alabama 0.99 1.13 -0.44 0.16
Alaska 1.95 1.07 2.04 -0.44
Arizona 1.76 -0.75 0.05 -0.83
Arkansas -0.14 1.12 0.11 -0.18
California 2.52 -1.54 0.60 -0.34
Colorado 1.51 -0.99 1.10 0.00
Connecticut -1.36 -1.09 -0.64 -0.12
Delaware 0.05 -0.33 -0.72 -0.88
Florida 3.01 0.04 -0.58 -0.10
Georgia 1.64 1.28 -0.34 1.08
Hawaii -0.91 -1.57 0.05 0.90
Idaho -1.64 0.21 0.26 -0.50
Illinois 1.38 -0.68 -0.68 -0.12
Indiana -0.51 -0.15 0.23 0.42
Iowa -2.25 -0.10 0.16 0.02
Kansas -0.80 -0.27 0.03 0.21
Kentucky -0.75 0.96 -0.03 0.67
Louisiana 1.56 0.87 -0.78 0.45
Maine -2.40 0.38 -0.07 -0.33
Maryland 1.76 0.43 -0.16 -0.56
Massachusetts -0.49 -1.47 -0.61 -0.18
Michigan 2.11 -0.16 0.38 0.10
Minnesota -1.69 -0.63 0.15 0.07
Mississippi 1.00 2.39 -0.74 0.22
Missouri 0.70 -0.26 0.38 0.23
Montana -1.19 0.54 0.25 0.12
Nebraska -1.27 -0.19 0.18 0.02
Nevada 2.87 -0.78 1.16 0.31
New Hampshire -2.38 -0.02 0.04 -0.03
New Jersey 0.18 -1.45 -0.76 0.24
New Mexico 1.98 0.14 0.18 -0.34
New York 1.68 -0.82 -0.64 -0.01
North Carolina 1.12 2.23 -0.86 -0.95
North Dakota -2.99 0.60 0.30 -0.25
Ohio -0.23 -0.74 -0.03 0.47
Oklahoma -0.31 -0.29 -0.02 0.01
Oregon 0.06 -0.54 0.94 -0.24
Pennsylvania -0.89 -0.57 -0.40 0.36
Rhode Island -0.86 -1.49 -1.37 -0.61
South Carolina 1.32 1.93 -0.30 -0.13
South Dakota -1.99 0.82 0.39 -0.11
Tennessee 1.00 0.86 0.19 0.65
Texas 1.36 -0.41 -0.49 0.64
Utah -0.55 -1.47 0.29 -0.08
Vermont -2.80 1.40 0.84 -0.14
Virginia -0.10 0.20 0.01 0.21
Washington -0.22 -0.97 0.62 -0.22
West Virginia -2.11 1.42 0.10 0.13
Wisconsin -2.08 -0.61 -0.14 0.18
Wyoming -0.63 0.32 -0.24 -0.17-
Explained Variance (
pca_output$sdev ^ 2)
![]()