K-Means Clustering
MATH/COSC 3570 Introduction to Data Science
K-Means Clustering
Partition observations into \(K\) distinct, non-overlapping clusters: assign each to exactly one of the \(K\) clusters.
Must pre-specify the number of clusters \(K \ll n\).
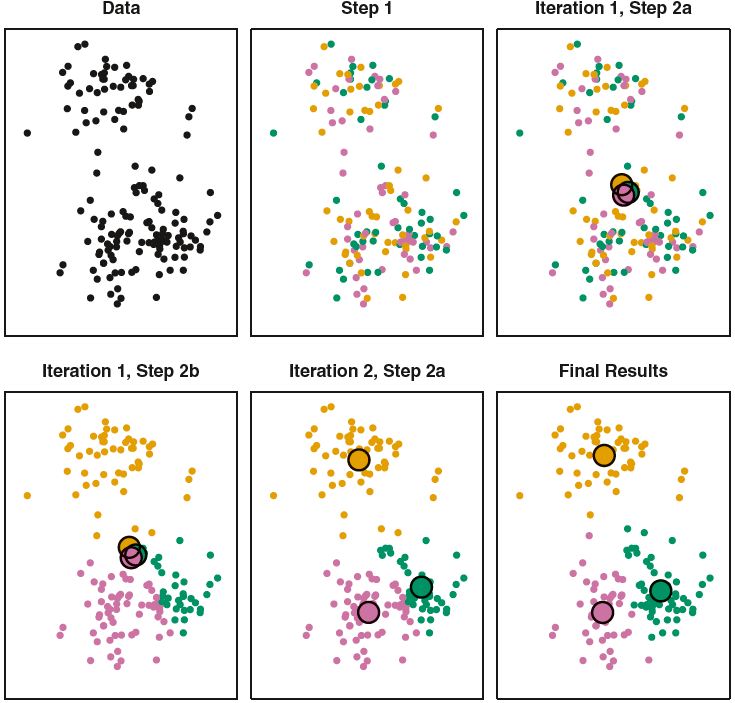
K-Means Illustration
Data (Let’s choose \(K=2\))

K-Means Algorithm
- Choose a value of \(K\).
- Randomly assign a number, from 1 to \(K\), to each of the observations.
- Iterate until the cluster assignments stop changing:
- [1] For each of the \(K\) clusters, compute its cluster centroid.
- [2] Assign each observation to the cluster whose centroid is closest.
K-Means Illustration
Random assignment

K-Means Algorithm
- Choose a value of \(K\).
- Randomly assign a number, from 1 to \(K\), to each of the observations.
- Iterate until the cluster assignments stop changing:
- [1] For each of the \(K\) clusters, compute its cluster centroid.
- [2] Assign each observation to the cluster whose centroid is closest.
K-Means Illustration
Compute the cluster centroid
K-Means Algorithm
- Choose a value of \(K\).
- Randomly assign a number, from 1 to \(K\), to each of the observations.
- Iterate until the cluster assignments stop changing:
- [1] For each of the \(K\) clusters, compute its cluster centroid.
- [2] Assign each observation to the cluster whose centroid is closest.
K-Means Illustration
Do new assignment
K-Means Algorithm
- Choose a value of \(K\).
- Randomly assign a number, from 1 to \(K\), to each of the observations.
- Iterate until the cluster assignments stop changing:
- [1] For each of the \(K\) clusters, compute its cluster centroid.
- [2] Assign each observation to the cluster whose centroid is closest.
K-Means Illustration
Do new assignment

Compute the cluster centroid …
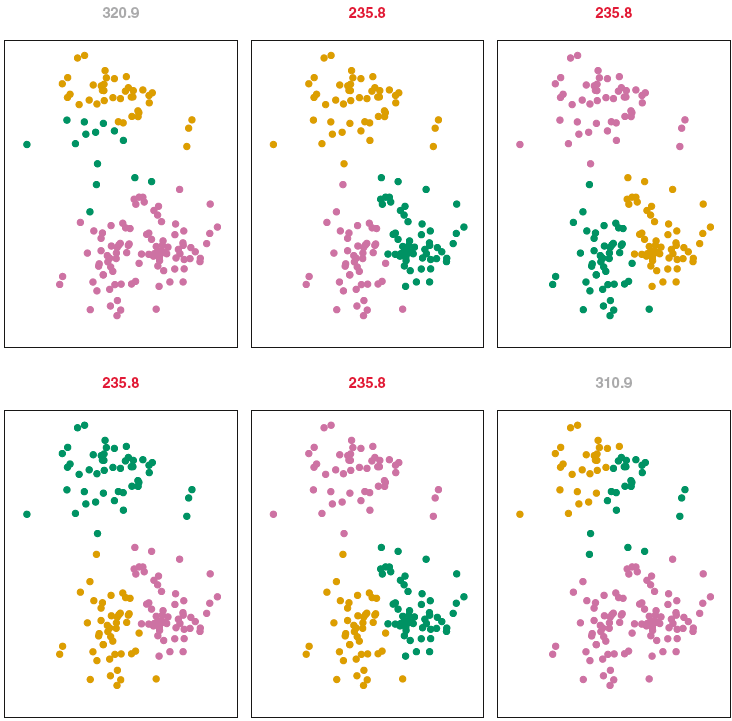
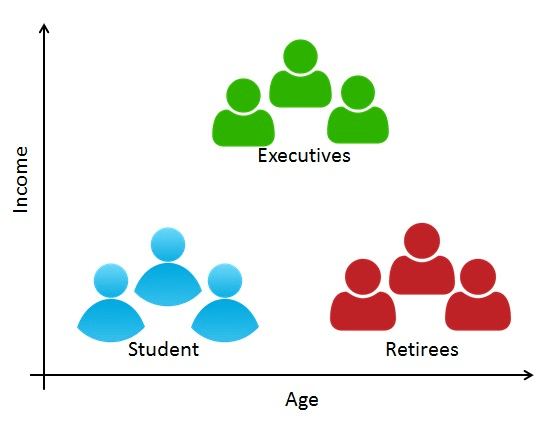
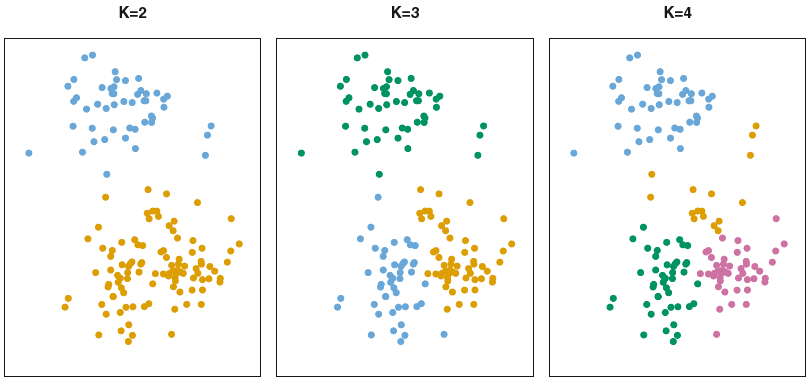
Data for K-Means
K-Means in R
- Steady-income family
- New college graduates/mid-class young family
- High socioeconomic class
K-Means in R: factoextra
Choose K: Total Withing Sum of Squares